➜ Conceptos básicos para #git | Capitulo 1
Teoría | Flujo básico y conceptos necesarios para entender git | Bienvenidos a este curso introductorio sobre Git, en que se desglosará parte por parte los comandos, como usarlo, ¿Qué es GitHub? entre otros detalles.
Esta primera lección será completamente teórica, y estaremos viendo lo que ves en el listado a continuación, desde entender que es eso del sistema de control de versiones, pasando por algunos comandos básicos, entender que es un repositorio, que son las ramas, y como es el siglo de vida de tus archivos una vez que usas git, esto incluye desde entender que significa traquear, que significa stage, y demas conceptos acorde, tambien estaremos viendo qué es eso de clonar, para que sirve una conexión remota, que es hacer push y que es hacer pull, pero recuerden que todo sera una aproximación teórica así que solo presten mucha atención, que es probable que todo sea nuevo para ti.
- ¿Qué es un sistema de control de versiones?
- Comando: git init, la carpeta .git y ¿Qué son los repositorios?
- ¿Qué es un commit?
- El ciclo de vida del estado de tus archivos: Sin seguimiento y En seguimiento
- ¿Qué son las ramas?¿Qué es Master?
- Comandos: git checkout, git branch, git merge
- ¿Qué son los repositorios remotos?
- ¿Qué es clonar? ¿Qué son las conexiones remotas?
- Comandos: git clone, git push, git fetch, git pull
¿Qué es un sistema de control de versiones?
Cada que alguien busca: ¿que es git? la respuesta que encontrarán en todos lados es que es un “sistema de control de versiones” que es lo correcto eso es lo que es, pero verlo con un ejemplo es mejor, observemos la imagen de mas abajo, eso es un caso típico, siempre que trabajas en un proyecto que no usa git, te topas con esto, tiendes a copiar tu proyecto, las veses que requieras para hacer cambios de los que no estes seguro, pero como tienes una copia, no hay problema porque esa copia es como una version segura a la cual volver si algo sale mal en las demas copias, esto pasa porque hasta llegar a la version final, hacemos multiples cambios, y luego copiamos la version final en un pendrive para llevarlo con nosotros, pero y si te diria que puedes mantener esos cambios sin necesidad de esta haciendo copias de carpetas completas, es decir unicamente conservar un historico de cada control + s que tu consideres especial, por alguna razon, ya se aun cambio pesado, o un cambio que del que no estes muy seguro, todo para volver a ellos cuando lo requieras; bueno pues la forma de lograr eso es con git, tener un control de versiones es solo conservar los cambios que hiciste, esos control + s en tu visual code, los puedes conservar, pero ¿como? Bueno hay que entender git y como trabaja para entenderlo.

Comando: git init, la carpeta .git y ¿Qué son los repositorios?
 Imaginemos que la carpeta de la imagen anterior es un proyecto tuyo en el que quieres usar git, ¿cómo empiezas?, aquí vendria el primer concepto del que quiero hablarles, git init, para empezar a usar git en cualquier proyecto tienes que usar el comando: “git init”, que lo que hace es iniciar el repositorio, un repositorio, como concepto del mundo git, es un almacen al que se le hara seguimiento, es decir es un proyecto en el que se usara git para tener ese control de versiones; ahora ¿que implica que tu carpeta sea un repositorio? bueno, primero aparecerá la carpeta .git, no la notaras, porque es una carpeta oculta, pero puedes saber que está ahí, porque si entras a las configuraciones del explorador de archivos y específicas ver archivos ocultos, ahi estara; esta carpeta es oculta, para evitar que interactúen con ella por error, dada su importancia, no la debes borrar, ni renombrar ni mover, nada, en su interior es donde git guarda sus configuraciones y donde también tiene una base de datos con todos los commits.
Imaginemos que la carpeta de la imagen anterior es un proyecto tuyo en el que quieres usar git, ¿cómo empiezas?, aquí vendria el primer concepto del que quiero hablarles, git init, para empezar a usar git en cualquier proyecto tienes que usar el comando: “git init”, que lo que hace es iniciar el repositorio, un repositorio, como concepto del mundo git, es un almacen al que se le hara seguimiento, es decir es un proyecto en el que se usara git para tener ese control de versiones; ahora ¿que implica que tu carpeta sea un repositorio? bueno, primero aparecerá la carpeta .git, no la notaras, porque es una carpeta oculta, pero puedes saber que está ahí, porque si entras a las configuraciones del explorador de archivos y específicas ver archivos ocultos, ahi estara; esta carpeta es oculta, para evitar que interactúen con ella por error, dada su importancia, no la debes borrar, ni renombrar ni mover, nada, en su interior es donde git guarda sus configuraciones y donde también tiene una base de datos con todos los commits.
¿Qué es un commit?
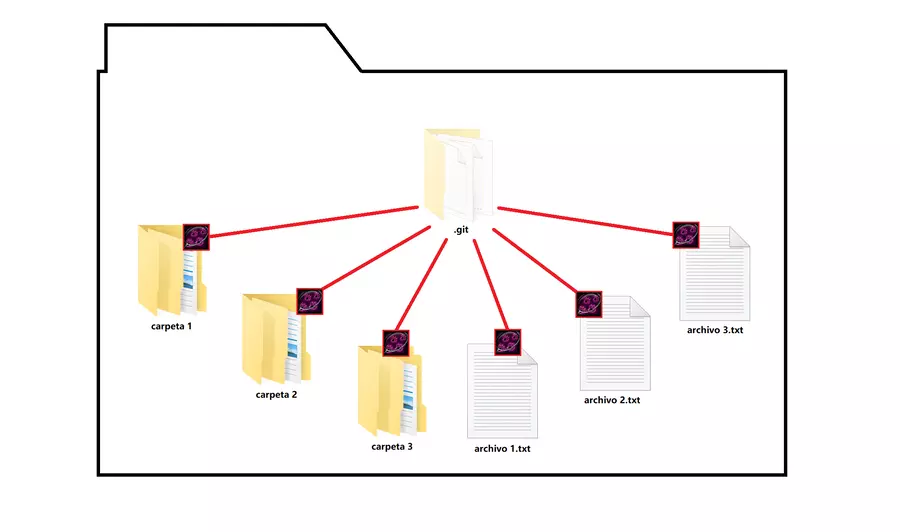 Commits, ese es otro concepto muy importante, un commit es un estado en el que se encuentran tus archivos que tu quieres conservar, los commits son las respuesta para evitar el uso de carpetas con nombres tipo “version final”, “version final 2”, “version final final”, etc, son el porqué del uso de git, y ¿cómo hacemos un commit? bueno, ahora que tu carpeta ya es un repositorio, puedes empezar a hacer commits, y el primer paso para hacerlo, es darle seguimiento a los archivos, es decir, en inglés, traquearlos, en la imagen anterior estoy usando el símbolo de la lupa siguiendo las huellas, para mostrar qué archivos están bajo seguimiento, una vez que todos los archivos están traqueados, ya puedes hacer tu commit, cabe aclarar que, la carpeta git init no debe traquearse, al ser esta la encargada de seguir los cambios en los archivos del repo, no necesitas traquearla, es más debes hacer como si no existiera, como se explicó antes; pero y ¿por qué traqueamos los archivos?
Commits, ese es otro concepto muy importante, un commit es un estado en el que se encuentran tus archivos que tu quieres conservar, los commits son las respuesta para evitar el uso de carpetas con nombres tipo “version final”, “version final 2”, “version final final”, etc, son el porqué del uso de git, y ¿cómo hacemos un commit? bueno, ahora que tu carpeta ya es un repositorio, puedes empezar a hacer commits, y el primer paso para hacerlo, es darle seguimiento a los archivos, es decir, en inglés, traquearlos, en la imagen anterior estoy usando el símbolo de la lupa siguiendo las huellas, para mostrar qué archivos están bajo seguimiento, una vez que todos los archivos están traqueados, ya puedes hacer tu commit, cabe aclarar que, la carpeta git init no debe traquearse, al ser esta la encargada de seguir los cambios en los archivos del repo, no necesitas traquearla, es más debes hacer como si no existiera, como se explicó antes; pero y ¿por qué traqueamos los archivos?
El ciclo de vida del estado de tus archivos: Sin seguimiento y En seguimiento
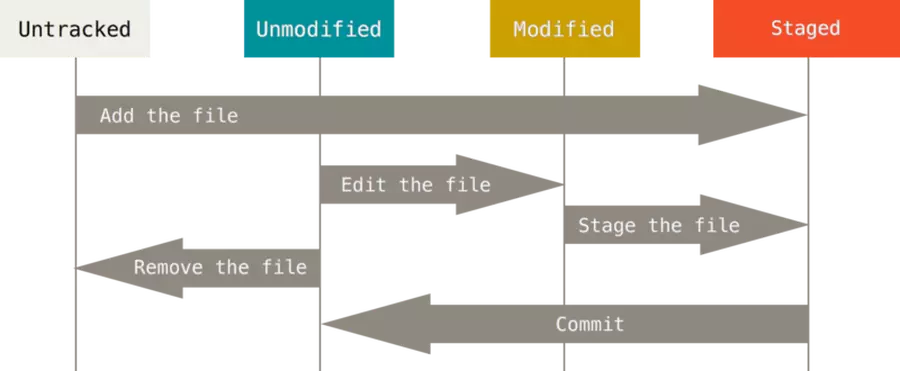
Para git el ciclo de vida de un archivo es como se ve en la imagen anterior, tus archivos pueden estar o sin traquear o traqueados, a su vez cuando ya están traqueados pueden estar en otros 3 estados que son: sin modificar, modificados o en stage, vamos con el primero, recuerden que imaginamos que nuestro ejemplo era un proyecto real, entonces los archivos 1, 2 y 3 no están vacíos, tienen contenido y ahora que tus archivos ya dejaron de estar untraked osea sin seguimiento, pasan al estado “en stage” o preparados (traducción aproximada) stage es el paso previo del commit; ese salto de dejar de estar “untraked” a pasar a “stage”, o pasar a estar traqueado, es necesario, obligatorio, porque con el, git ya tendrá un punto de partida que usará para darse cuenta cuando edites algo, por eso git necesita traquear tus archivos, para tener control de todo lo que sucede en la carpeta y decirte en que estado estan tus archivos, que si modificados, sin modificar o en stage.
¿Qué son las ramas?¿Qué es Master?
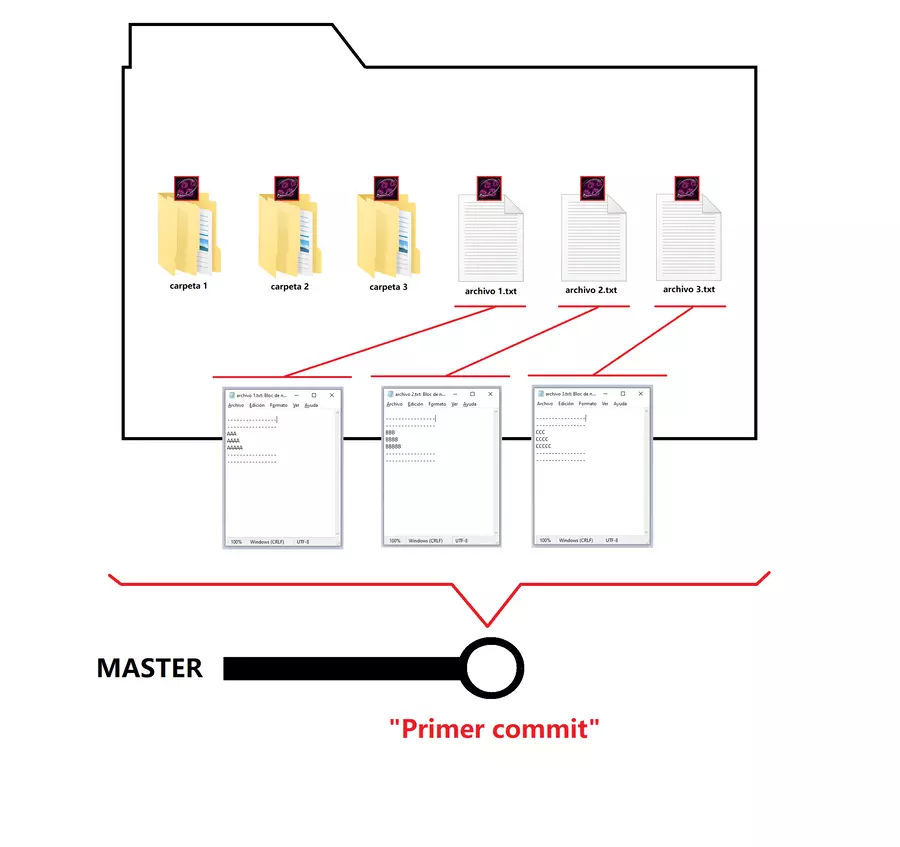 Una vez que el contenido está en stage, ya está listo para el commit, ¿pero donde se guardaría ese commit? el sistema que usa git para que nosotros sepamos dónde está nuestro commit, para volver a él cuando queramos es uno basado en ramas y aquí viene otro concepto interesante, las ramas, al principio cuando hicimos el git init, aparte del repositorio también se crea una rama inicial, llamada Master, las ramas son donde se almacenan un conjunto de commits para que en base a ellos creemos ramificaciones basados en distintos cambios que queramos hacer en nuestro proyecto. Ahora, para terminar el commit, el segundo y último paso es escribir un mensaje para ese commit, solo describe el cambio que hiciste y con eso basta. En este caso al ser de prueba, le pondré “primer commit” y listo, el commit se ve representado casi siempre como se ve en la imagen anterior, una bolita en la rama actual, Master.
Una vez que el contenido está en stage, ya está listo para el commit, ¿pero donde se guardaría ese commit? el sistema que usa git para que nosotros sepamos dónde está nuestro commit, para volver a él cuando queramos es uno basado en ramas y aquí viene otro concepto interesante, las ramas, al principio cuando hicimos el git init, aparte del repositorio también se crea una rama inicial, llamada Master, las ramas son donde se almacenan un conjunto de commits para que en base a ellos creemos ramificaciones basados en distintos cambios que queramos hacer en nuestro proyecto. Ahora, para terminar el commit, el segundo y último paso es escribir un mensaje para ese commit, solo describe el cambio que hiciste y con eso basta. En este caso al ser de prueba, le pondré “primer commit” y listo, el commit se ve representado casi siempre como se ve en la imagen anterior, una bolita en la rama actual, Master.
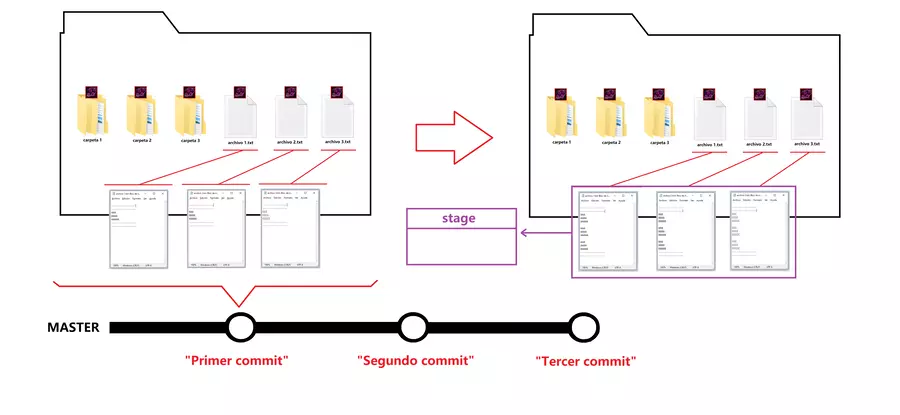 Entonces, hagamos un nuevo commit, para repasar todo el siglo, editas tus archivos 1, 2 y 3 y git detecta esa edición que hiciste, porque tus archivos ya están traqueados y git compara como estaban tus archivos en el último commit en el que aparecen, es decir el primer commit, con el como están ahora, es decir la última edición hecha, por cierto, digamos que en el segundo y tercer commit cambiamos algo en las carpetas y nada en los archivos ya que así el conflicto es solo con el primer commit; y al ser ambos contenidos diferentes, git hace que tus archivos pasen al estado de “modificado”, con el primer commit hecho tus archivos pasaron del estado en “stage” al estado “sin modificar” que significa que no es necesario pasar a stage, recuerden que pasar a stage es el paso obligatorio para hacer el commit, y git no te pedirá que pases a stage, si nada a cambiado, ahora como si se encontraron cambios, git te dice, tus archivos están modificados, debes pasarlos a stage, que es como esta cajita morada de la imagen de mas abajo. En tu siglo de vida, los archivos estaban en el estado modificado, el pasarlos a stage, es decir ponerlos en esa cajita, (un espacio de ram) es como se lo imaginaran, pasar al estado stage y tus cambios estarán ahí hasta que decidas hacer el commit, el cual una vez terminado, hará que tus archivos pasen al estado “sin modificar” nuevamente, repitiendo así el ciclo las veces que tu quieras, con los commit que tu quieras.
Entonces, hagamos un nuevo commit, para repasar todo el siglo, editas tus archivos 1, 2 y 3 y git detecta esa edición que hiciste, porque tus archivos ya están traqueados y git compara como estaban tus archivos en el último commit en el que aparecen, es decir el primer commit, con el como están ahora, es decir la última edición hecha, por cierto, digamos que en el segundo y tercer commit cambiamos algo en las carpetas y nada en los archivos ya que así el conflicto es solo con el primer commit; y al ser ambos contenidos diferentes, git hace que tus archivos pasen al estado de “modificado”, con el primer commit hecho tus archivos pasaron del estado en “stage” al estado “sin modificar” que significa que no es necesario pasar a stage, recuerden que pasar a stage es el paso obligatorio para hacer el commit, y git no te pedirá que pases a stage, si nada a cambiado, ahora como si se encontraron cambios, git te dice, tus archivos están modificados, debes pasarlos a stage, que es como esta cajita morada de la imagen de mas abajo. En tu siglo de vida, los archivos estaban en el estado modificado, el pasarlos a stage, es decir ponerlos en esa cajita, (un espacio de ram) es como se lo imaginaran, pasar al estado stage y tus cambios estarán ahí hasta que decidas hacer el commit, el cual una vez terminado, hará que tus archivos pasen al estado “sin modificar” nuevamente, repitiendo así el ciclo las veces que tu quieras, con los commit que tu quieras.
Comandos: git checkout, git branch, git merge
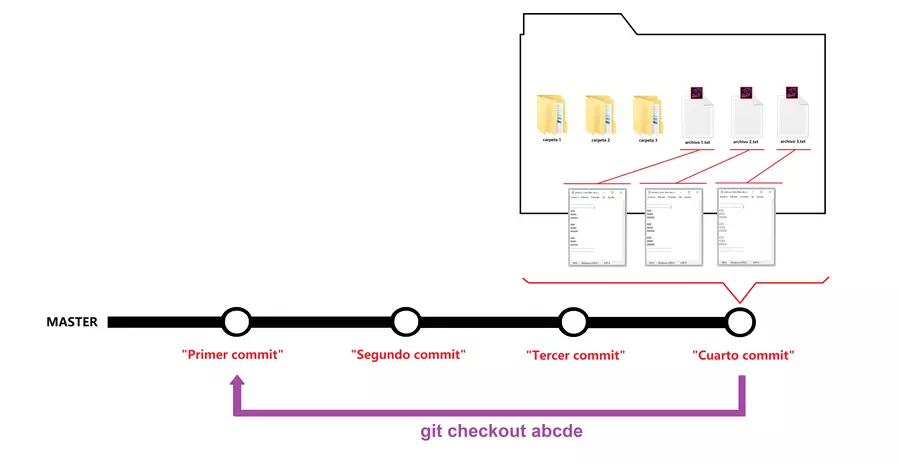 Tu puedes hacer los commits que gustes, y asi puede que llegue un punto en el que quieras volver atrás, a un punto en tu proyecto en el que dijiste, nose si lo que hare mas adelante estara bien o estara mal asi que me gustaria tener un punto de retorno, imaginemos que ese punto es el primer commit, pero hicimos todo este nuevo commit de repaso para, desde aquí, volver a un punto anterior de nuestro proyecto ¿recuerdan? ese punto era el primer commit, el proyecto actualmente está como se ve en la carpeta de la imagen anterior, si queremos volver a como estaba todo en el primer commit debemos usar el comando: git checkout al que puedes darle el nombre de una rama para ir a su último commit, (la linea morada) si le damos master, seria para volver a master, pero estando en otra rama, claro; aunque también puedes darle al comando un commit en específico, para lo cual usas el id alfanumérico que acompaña a cada commit, de esa forma lo que verás en tus archivos será el cómo estaban cuando hiciste el primer commit.
Tu puedes hacer los commits que gustes, y asi puede que llegue un punto en el que quieras volver atrás, a un punto en tu proyecto en el que dijiste, nose si lo que hare mas adelante estara bien o estara mal asi que me gustaria tener un punto de retorno, imaginemos que ese punto es el primer commit, pero hicimos todo este nuevo commit de repaso para, desde aquí, volver a un punto anterior de nuestro proyecto ¿recuerdan? ese punto era el primer commit, el proyecto actualmente está como se ve en la carpeta de la imagen anterior, si queremos volver a como estaba todo en el primer commit debemos usar el comando: git checkout al que puedes darle el nombre de una rama para ir a su último commit, (la linea morada) si le damos master, seria para volver a master, pero estando en otra rama, claro; aunque también puedes darle al comando un commit en específico, para lo cual usas el id alfanumérico que acompaña a cada commit, de esa forma lo que verás en tus archivos será el cómo estaban cuando hiciste el primer commit.
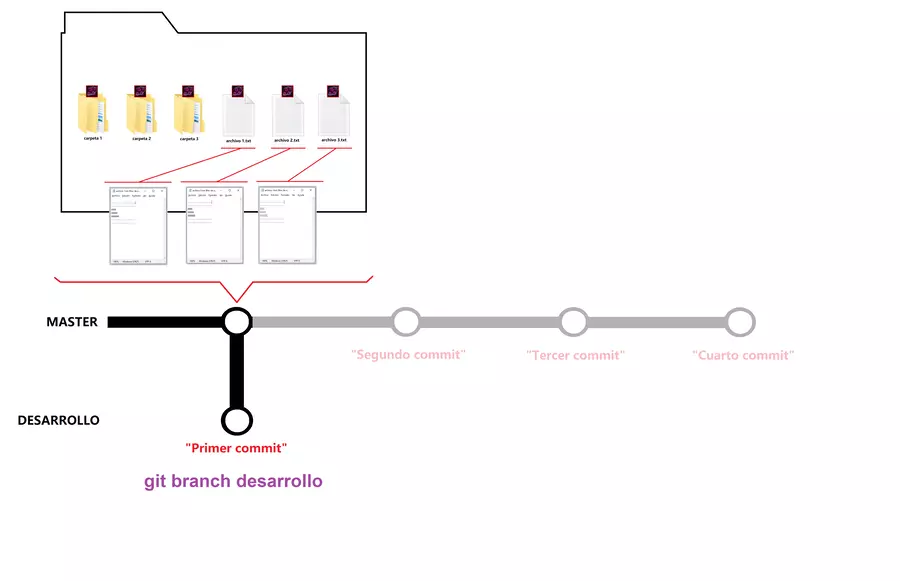 Aprovechando que volvimos al primer commit, retomemos un concepto que deje en el aire, gracias a este sistema de ramas, podemos crear ramificaciones, y este es un buen punto para iniciar una rama, luego de hecho el checkout a tu primer commit, tu puedes elegir convertir esto en una nueva rama o volver al cuarto commit, hagamos lo primero, el comando para crear ramas es uno llamado git branch, seguido del nombre que quieres ponerle a tu rama, puede ser por ejemplo “desarrollo” una vez creada la rama, pasaras a tener 2 ramas, el primer commit de tu rama desarrollo, es el mismo del que partimos al usar el comando branch, pero que gráficamente se suele hacer esto de ponerlo como repetido, aunque realmente es el mismo, entonces tu “primer commit” de tu nueva rama es el mismo del de tu rama master, si hubieras hecho la rama desde el segundo commit, hubiera sido el segundo commit el que se repita, o el tercero o el cuarto; es el mismo commit pero siendo apuntado por 2 ramas diferentes.
Aprovechando que volvimos al primer commit, retomemos un concepto que deje en el aire, gracias a este sistema de ramas, podemos crear ramificaciones, y este es un buen punto para iniciar una rama, luego de hecho el checkout a tu primer commit, tu puedes elegir convertir esto en una nueva rama o volver al cuarto commit, hagamos lo primero, el comando para crear ramas es uno llamado git branch, seguido del nombre que quieres ponerle a tu rama, puede ser por ejemplo “desarrollo” una vez creada la rama, pasaras a tener 2 ramas, el primer commit de tu rama desarrollo, es el mismo del que partimos al usar el comando branch, pero que gráficamente se suele hacer esto de ponerlo como repetido, aunque realmente es el mismo, entonces tu “primer commit” de tu nueva rama es el mismo del de tu rama master, si hubieras hecho la rama desde el segundo commit, hubiera sido el segundo commit el que se repita, o el tercero o el cuarto; es el mismo commit pero siendo apuntado por 2 ramas diferentes.
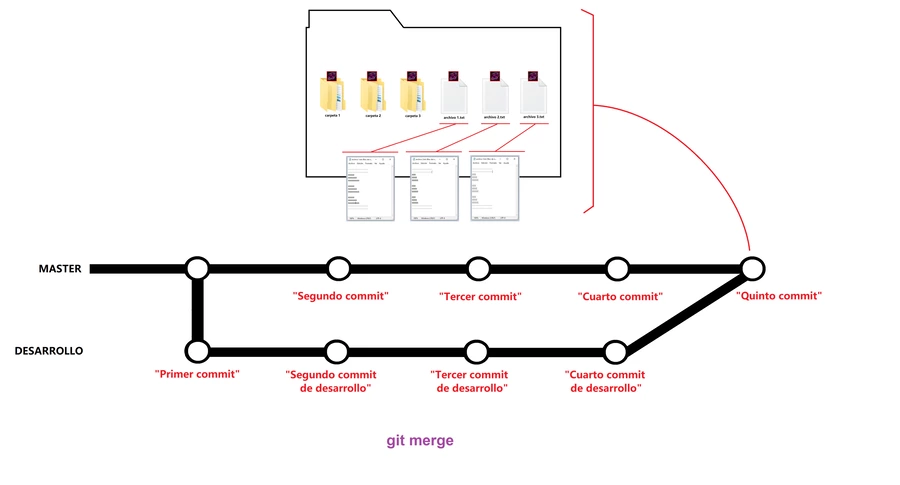
Como se lo imaginaran puedes seguir haciendo los commits que gustes en tu nueva rama, sin necesidad de temer por perder lo avanzado anteriormente, porque eso está en el cuarto commit, intacto, si queremos volver a él simplemente hacemos checkout a master; pero antes de eso algo que normalmente pasa es que tienes que fusionar tus ramas en algún momento, digamos que en tu rama desarrollo hiciste pruebas particulares en el archivo 1 y esas pruebas funcionaron, entonces ya puedes unirlas a tu rama, master, para esto usamos un comando llamado merge que se encargará de ver linea a linea el contenido y agregar las líneas nuevas de código que hay en archivo 1, y pasarlas al archivo 1 de master, si hay conflicto es decir si alteraste las mismas líneas, el comando te lo hará saber. Respecto a esto último es bueno que sepan que lo normal es que tengas una rama como desarrollo en la que hagas tus cambios, no trabajas directamente en master porque así tienes una rama principal limpia de errores lista para subir al repositorio remoto.
¿Qué son los repositorios remotos?
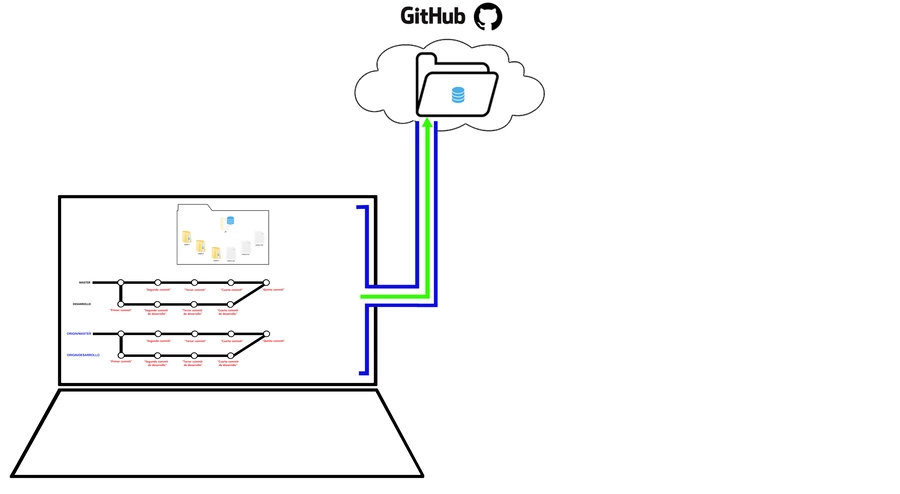
Cuando trabajamos en local en nuestros pcs de confianza no suele haber necesidad de subir tu proyecto a un repositorio remoto, pero los tiempos han cambiado, esto es obligatorio, ya no solo porque a nivel profesional puedes exponer tu trabajo, sino porque a nivel laboral puedes trabajar con programadores de todo el mundo, compartiendo un repositorio remoto; los servicios más comunes que ofrecen esto son 2: gitHub y gitLab, en esta serie, usaremos gitHub, y a todo esto ¿qué significa tener un repositorio remoto? es simple miren, tu puedes subir una o todas las rama de tu proyecto a un repositorio remoto, que no es más que un repositorio como el que tenemos en local, pero en un servidor que tiene git instalado, ese entorno es GitHub y para poder subir tu rama necesitas abrir una conexión remota, a la que normalmente se le llama origin y que entre otras cosas te crea una nueva rama remota, (origin/master) pero de eso hablamos en un momento, una vez hecha la conexión remota ya podemos subir nuestra rama local, y una vez subida, en el repo remoto ahora habitarán nuestros commits, al ser remoto tu solo debes compartir el link que tiene este repositorio, y demás programadores podrán verlo y clonarlo.
¿Qué es clonar? ¿Qué son las conexiones remotas?
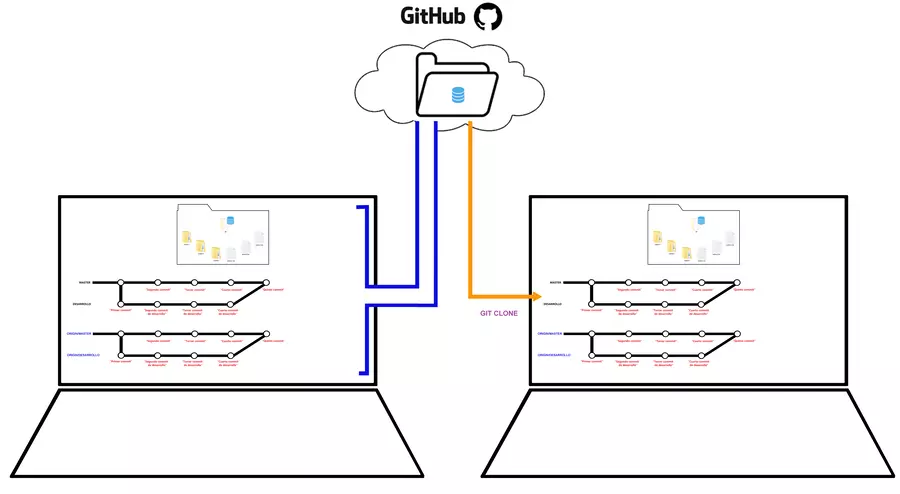
Los servidores de gitHub tienen alcance global, y al tener un repo alojado en su nube, es decir hacerlo remoto, puedes obviamente, bajarlo, descargarlo, aunque esa no es la palabra exacta, se dice clonar, porque lo que pasa es que se crea una carpeta en la pc en la que se está haciendo la clonación, con todo el proyecto, pero no solo con los contenidos como archivos y carpetas, sino también se hace una copia del historial de commits, para que puedas ver los cambios que han sucedido hasta llegar a la versión más reciente; todo para que a partir de ahí tu puedas empezar a colaborar en ese repo, si es de un tercero, necesitarás permisos, pero si es tuyo no tendrás problemas. Para clonar un repositorio se usa el comando “git clone” y algo mas que sucede al ejecutar este comando, es que se crea una conexión remota llamada “origin” (origen) que apunta al repositorio clonado, esta conexión existe porque git sabe que eventualmente necesitarás comunicarte con un repositorio remoto, y realmente cualquier repositorio puede tener esta conexión remota, no necesariamente uno repositorio que haya sido clonado ¿y que usos tiene?
Comandos: git clone, git push, git fetch, git pull
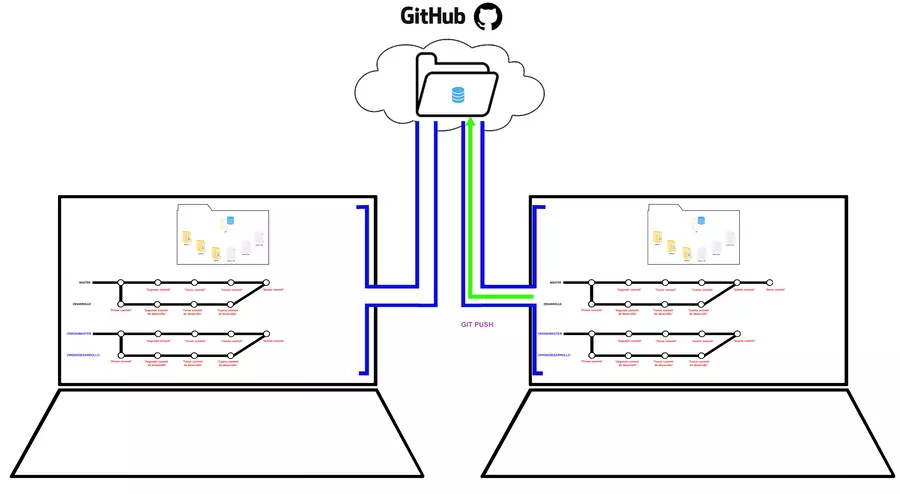
La conexión remota sirve para facilitarnos la subida de commits nuevos, o hacer un push, en la imagen la pc de la derecha agregó un nuevo commit, ese nuevo commit debe subirse al repositorio remoto para mantener al día al resto de colaboradores, como el de la pc de la izquierda que podrías ser tú, que le diste permiso de participar en el repositorio al de la pc de la derecha y por tanto ahora tienes que estar pendiente de los commits nuevos; y justamente es ese otro de los usos de la conexión remota, puedes solicitar traer los nuevos cambios que están en el repositorio remoto; ese “nuevo commit” no existe en el historial de commits de la pc de la izquierda, por tanto debes traerlo, o hacer un fetch, con ello tienes los commits, que se van a la rama remota; recuerdan que se crea una rama remota al abrir una conexión remota, esa rama remota, es donde estarán tus comits, listos para ser consultados, o mucho mejor, ser fusionados a tu master con merge.
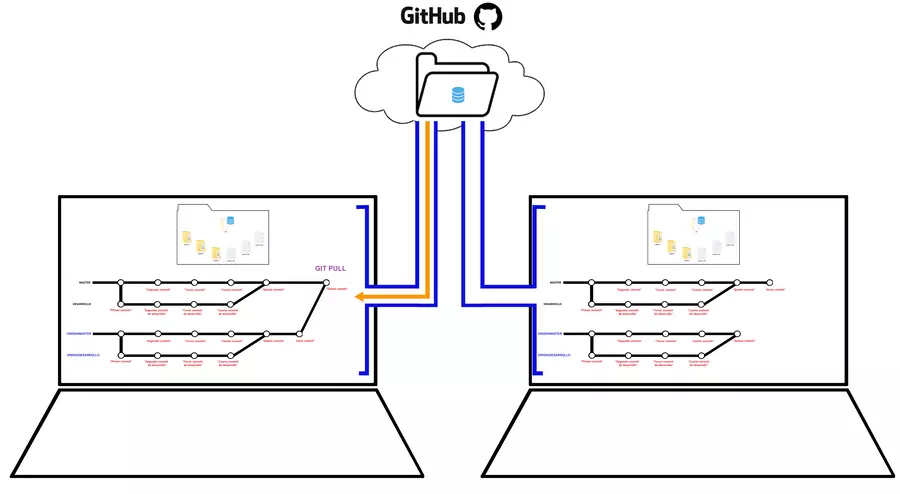
Estos últimos pasos se pueden hacer en uno solo, es decir el fetch y el merge trabajando juntos, se le conoce como git pull, comando que trae y fusiona tus cambios, directamente en tu rama master y así amigos es en resumidas cuentas mucho de lo que puedes hacer con git creo que hemos avanzado bastante contenido de cómo se trabaja con git, contenido que iremos ampliando parte por parte ahora si con comandos en la parte práctica de este curso.
1324 visitas
Capítulo 2 – Instalación de #git en Windows paso a paso | Capitulo 2 »
